February 3, 2026
security incident reportsincident responseiso 27001grc reportingaudit preparation
Security Incident Reports: Proven Steps for ISO Audits
Learn how to craft effective security incident reports that satisfy auditors and align with ISO standards.
22 min readAI Gap Analysis

Let's be honest: a poorly written security incident report is more than just a documentation hiccup. It's a direct route to a failed audit. These reports are supposed to be the definitive proof of your organization’s diligence, but I've seen them fall apart under the slightest pressure far too often. The core problem is they lack the specific, evidence-backed details that auditors and regulators need to see.
Why Most Security Incident Reports Fail Audits
Staring at an audit finding for an incomplete incident report is a painfully common experience for GRC teams. The issue is that most reports are written like a simple log of events. They aren't crafted as a defensible narrative that proves your controls actually work. This turns them into a massive compliance headache, because they fail to connect the dots between what happened, why it happened, and what you did to make sure it never happens again.
The goal should always be an "evidence-ready" report. Think of it as a document designed from the ground up to serve as undeniable proof of your diligence. This means getting past generic descriptions and documenting every single action with absolute precision.
Common Pitfalls That Invite Scrutiny
There are a few recurring mistakes that consistently turn routine reports into major compliance problems. Auditors are trained to sniff out these weaknesses, and they usually fall into a few key areas:
- Vague Root Cause Analysis: Simply writing "user error" is an immediate red flag. A proper analysis goes much deeper. Was it a lack of training? Were the security controls inadequate and allowed the error to happen in the first place? That’s what they want to know.
- Poorly Documented Remediation: Stating "patched server" is practically useless. An auditor needs to see the evidence. Which specific patch was applied? When was it deployed? How did you verify the fix actually worked? Without that proof, your remediation is just an empty claim.
- Missing or Inconsistent Timestamps: A precise timeline isn't optional; it's mandatory. Vague entries like "sometime in the afternoon" or, even worse, conflicting timestamps between different logs, completely undermine the report's credibility. It suggests your response was chaotic and uncontrolled.
- Ambiguous Impact Statements: Describing the impact as "some files were accessed" won't cut it. A solid report quantifies the damage. How many files? What kind of data? Which specific users were affected? Be specific.
An incident report shouldn't just tell a story; it must prove it. Every claim, from the moment of detection to the final lessons learned, needs to be supported by clear, verifiable evidence. This is the core principle that separates a passable report from one that sails through an ISO audit.
The stakes here are incredibly high. Cyberattacks are only getting more complex and frequent. The global cost of cybercrime has ballooned to $10.5 trillion, making it the world's third-largest "economy" behind only the U.S. and China. When you consider that ransomware is involved in 44% of analyzed breaches and that less than a quarter of all cybercrimes are even reported, the pressure to document your response properly is immense. You can dig into more of these stats in the Cybersecurity Almanac 2025.
Understanding these common failure points is the first step toward building a more resilient reporting process—a critical piece of the puzzle when you're preparing for demanding ISO 27001 audits.
The Anatomy of An Evidence-Ready Incident Report
When you're building a security incident report, your real audience isn't just your CISO—it's the auditor who will scrutinize it months later. The goal isn't just to list what happened; it's to build an airtight case that proves your team acted with due diligence and that your controls held up. This turns a simple document into a piece of defensible evidence.
A solid report leaves zero room for an auditor's imagination. Every field, every timestamp, and every conclusion must be clear, concise, and directly support the incident's story from detection to resolution. This is what separates a report that sails through an audit from one that kicks off a painful string of follow-up questions and, ultimately, findings.
Initial Detection and Classification
The first few moments of an incident feel like a whirlwind, but your documentation needs to be the calm in the storm. The very first thing to nail down is who found what, how they found it, and the exact time it happened. Was it an automated alert from your SIEM, a sharp-eyed user reporting a suspicious email, or a heads-up from a third party? That first entry on your timeline is critical—it's the starting gun for your entire response.
Next comes classification, and this is where a lot of reports fall flat. It’s not about just slapping a label on it. A proper classification defines the severity and potential business impact, which is what justifies the resources you throw at the problem.
For example, a malware outbreak that’s spreading laterally is an obvious "High Severity" incident. On the other hand, a single lost company laptop with full-disk encryption might be a "Low Severity" event. Your report must show your work, explaining why you made that call, ideally by referencing a predefined incident response matrix your team already uses.
The flowchart below shows what happens when documentation has gaps—it's a fast track to a failed audit.
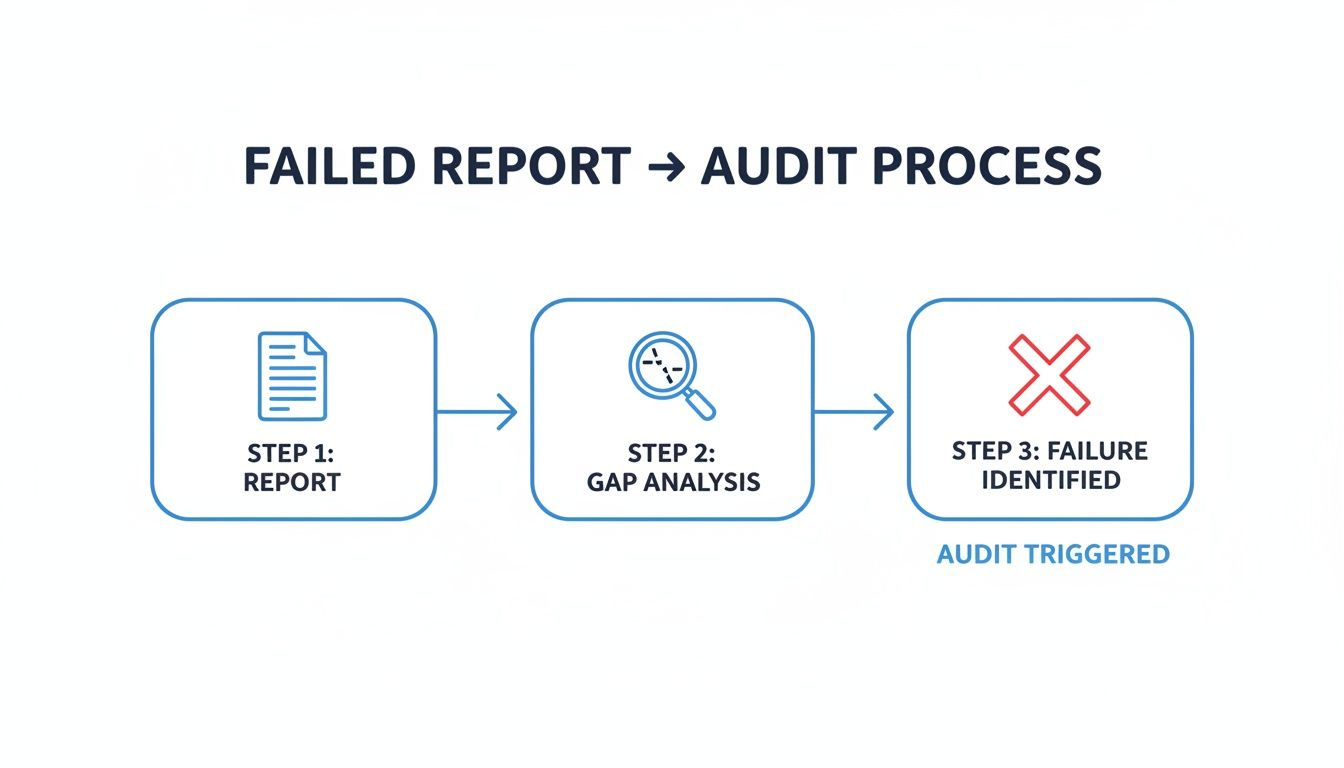
This visual really drives home how an incomplete report creates an evidence gap an auditor will spot from a mile away, leading to a failed assessment of that control.
To help you structure this, here’s a breakdown of the essential fields every audit-ready report should contain.
Essential Fields for an Audit-Ready Incident Report
This table outlines the critical components of a comprehensive security incident report, explaining the purpose of each field and providing examples for clarity.
| Report Field | Purpose and Key Details | Example Entry |
|---|---|---|
| Incident ID | A unique, non-sequential identifier for tracking. Establishes the official record. | SIR-2024-048 |
| Detection Timestamp (UTC) | The precise moment the incident was first detected. This is the starting point of the response SLA. | 2024-10-26 14:32:05 UTC |
| Detection Source | Who or what identified the issue. This validates your monitoring and reporting channels. | SIEM Alert (Rule ID: 34-Malware-C2-Beacon) or User Report (Ticket #INC98765) |
| Incident Classification | The assigned severity and type, based on a predefined matrix. Justifies the response level. | Severity: High, Type: Malware Outbreak (Ransomware) |
| Incident Summary | A concise, one-paragraph overview of the event, its impact, and the final outcome. Written for leadership. | A ransomware variant (Qakbot) was detected on 3 servers and 15 workstations. It was contained within 45 minutes, and all systems were restored from backups. No data exfiltration was identified. |
| Business Impact | A specific, quantified assessment of the damage to data, systems, operations, and reputation. | Disruption of the internal billing system for 3 hours. 2,500 customer PII records were exposed but not exfiltrated. |
| Event Timeline | A detailed, chronological log of every action taken by the response team. | 14:35 UTC: SRV-04 isolated from network (SOC Analyst Jane Doe). Justification: Prevent lateral movement. |
| Root Cause Analysis (RCA) | The ultimate "why." Identifies the underlying weakness that allowed the incident to occur. | A critical vulnerability (CVE-2023-38831) in a public-facing WinRAR instance was unpatched, allowing for initial code execution. |
| Containment & Eradication | Specific technical steps taken to stop the bleeding and remove the threat from the environment. | Containment: Blocked C2 server IPs at the firewall. Eradication: Re-imaged 18 affected machines. |
| Remediation & Lessons Learned | Actionable steps to prevent recurrence. This is what auditors want to see to close the loop. | Remediation: Deployed patch for CVE-2023-38831 to all endpoints. Lessons Learned: Review and improve vulnerability scanning cadence. |
| Status & Closure Date | The final status of the incident and the date it was officially closed. | Status: Closed, Date: 2024-10-28 11:00:00 UTC |
Having these fields populated with clear, factual information creates a powerful narrative that demonstrates competence and control to any auditor.
Building a Detailed Event Timeline
The timeline is the spine of your entire report. It needs to be an immutable, chronological log of every single significant action taken. If this section is vague, you're practically inviting an auditor to start digging.
Make sure every entry includes these four things:
- Exact Timestamp (UTC): Standardizing on UTC is non-negotiable. It eliminates any confusion across time zones.
- Action Taken: Be specific. "Isolated host SRV-04 from the production network" is good. "Handled the server" is not.
- Actor: Who did it? Note the name or team responsible, like "SOC Analyst Jane Doe" or "Network Engineering Team."
- Justification: Briefly explain why the action was taken. "To prevent further malware propagation" tells the auditor you were thinking strategically.
This level of detail creates a rock-solid audit trail, showing a methodical response instead of a chaotic scramble.
An auditor reads a timeline not just to see what happened, but to judge the maturity of your response process. Gaps, long delays, or fuzzy descriptions are immediate red flags that signal a lack of control.
Defining the Scope and Business Impact
Once the fire is out, your report has to clearly define the extent of the damage. This means getting granular with the facts—auditors can verify specifics, but they’ll tear apart generalities.
For a data leak incident, your report needs to answer:
- Data: What kind of records were exposed? Was it customer PII, internal financial data, or something else?
- Systems: Which specific databases, servers, or cloud storage buckets were hit?
- Users: Exactly how many user accounts were affected, and what were their access levels?
If you're dealing with a malware outbreak, the focus shifts:
- Systems: How many endpoints and servers were infected? Provide a number.
- Services: Were any business-critical services disrupted or degraded? Name them.
- Data: Did the malware exfiltrate, encrypt, or corrupt any data?
Framing the impact in real business terms is key. Stating that "2,500 customer records containing PII were exfiltrated from the primary CRM database" is infinitely more credible than a vague statement like "some customer data was stolen." This precision satisfies auditors and gives your leadership the concrete details they need to make decisions, especially when it comes to regulatory reporting.
Documenting Your Investigation and Root Cause
This is where a good incident report becomes a great one. It's also where many fall apart. Moving from documenting what happened to explaining why it happened requires a completely different mindset—one rooted in forensic diligence. A shallow investigation or a half-baked root cause analysis (RCA) is an instant red flag for any auditor. It tells them you're more interested in closing tickets than in fixing the real, underlying problems.
To build an unshakable audit trail, you have to meticulously document every single step of your investigation. This isn't just a simple checklist of actions. You're preserving digital evidence in a way that proves your analysis was thorough, impartial, and can be trusted by an outside party. Think of it as creating a narrative that someone else can follow from start to finish.
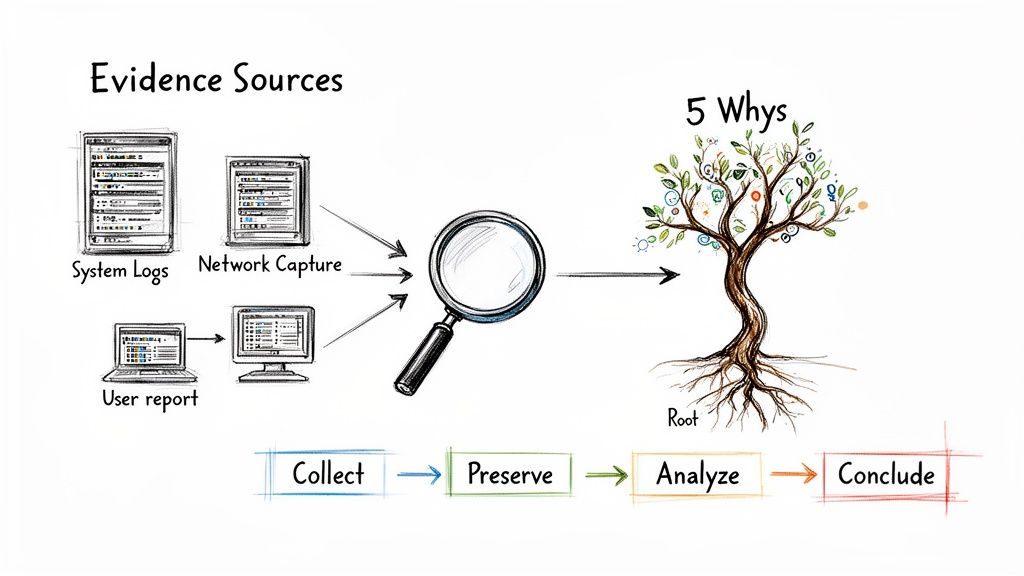
Gathering and Preserving Digital Evidence
Strong evidence is the bedrock of your entire investigation. Your job is to pull together artifacts from all kinds of sources and, just as importantly, ensure their integrity is maintained. This creates a chain of custody that an auditor can actually rely on.
Key evidence sources usually include:
- System Logs: Pull everything you can from affected servers, endpoints, and applications. We're talking event logs, authentication logs, and any application-specific records you can get your hands on.
- Network Traffic Captures: If you have them, full packet captures (PCAPs) are gold. At a minimum, NetFlow data can be a lifesaver for tracing an attacker's path and spotting command-and-control (C2) chatter.
- User Reports and Interviews: Never discount the human element. Document statements from the person who first spotted the issue or anyone else who noticed something strange. Their perspective adds crucial context that logs alone can't provide.
- System Images: For critical systems, taking a full forensic image is non-negotiable. It freezes the state of the machine so you can perform a deep analysis without contaminating the original evidence.
It's also critical to document the tools you used for collection. Don't just say "we looked at the network." Instead, write something like, "we used Wireshark to capture network traffic from the affected VLAN between 14:30 and 16:00 UTC." That level of detail demonstrates a professional, methodical approach and is a core part of any solid cybersecurity risk assessment.
Applying the 5 Whys to Uncover the Real Root Cause
One of the most common failures I see in incident reports is stopping the investigation too soon. Pointing to a phishing email as the cause isn't a root cause analysis—it's just identifying a symptom. To truly satisfy an auditor, you have to dig deeper and expose the process or technology gaps that allowed the attack to work in the first place.
The "5 Whys" is a deceptively simple technique that works wonders here. By just repeatedly asking "why," you can peel back the layers of an incident until you get to the core issue.
Let's walk through a common scenario: a cloud misconfiguration that led to a data leak.
Scenario: A Cloud Storage Bucket Exposed Publicly
-
Why #1: Why was the data exposed?
- A developer set an S3 bucket's permissions to 'public-read.'
-
Why #2: Why did the developer do that?
- They needed to share a file with an external contractor and figured this was the quickest way.
-
Why #3: Why was that the "quickest way"?
- The official process for creating a secure, pre-signed URL was buried in old documentation and required a support ticket with a 24-hour turnaround time.
-
Why #4: Why was the official process so painfully slow?
- It was designed years ago without any automation, and the cloud governance team is completely understaffed.
-
Why #5: Why didn't our security tools catch and fix this?
- Our Cloud Security Posture Management (CSPM) tool was only configured to scan for misconfigurations once a week, not in real-time.
See the difference? This analysis shifts the root cause from "a developer made a mistake" to "we have an inadequate process, a lack of automation, and an insufficient monitoring cadence." That’s the kind of deep insight an auditor is looking for because it points to meaningful, systemic fixes.
Documenting a Third-Party Vendor Incident
Your investigation can't stop at your own firewall, especially now that supply chains are such a popular target. When a third-party vendor is the source of an incident, your report needs to clearly document your due diligence in managing that relationship. The 2025 SecurityScorecard Global Third-Party Breach Report makes this painfully clear, revealing that 35.5% of all breaches worldwide now originate from third-party vendors. The situation is particularly dire in Northeast Asia, where third parties are implicated in an astonishing 54.3% of breaches. You can dive into the specifics in the full breach report on SecurityScorecard.com.
For these incidents, make sure your report includes:
- A complete timeline of your communications with the vendor.
- The evidence you requested from them (like their own incident report or logs).
- The specific actions you took to contain the impact on your own environment.
This level of detail proves to auditors that you are proactively managing your supply chain risk, not just waiting for the next fire.
Mapping Remediation and Lessons Learned to ISO
Let's be clear: a security incident isn't really over just because you've contained the immediate threat. From a compliance perspective, especially under a framework like ISO 27001, the response lifecycle only truly ends when you’ve documented how you’re going to stop it from happening again.
This is the critical step that turns a reactive firefight into a proactive demonstration of a mature, continuously improving Information Security Management System (ISMS).
Auditors are trained to hunt for this closed loop. They don’t just want to see that you patched the server or reset a password. They need to see hard evidence that the incident triggered a meaningful, positive change in your security posture. This is where your security incident reports become an essential link in the compliance chain, proving your ISMS is a living system, not just a dusty binder of policies.
Turning Technical Fixes into Formal CAPAs
The on-the-ground technical fixes—blocking a malicious IP, patching a vulnerability—are just the beginning of the story for an auditor. To make sense in a compliance context, these actions have to be translated into the formal language of Corrective and Preventive Actions (CAPAs). This process is how you formalize your response and create the clean, auditable trail of improvement they need to see.
For every CAPA you document in your incident report, you need to nail down a few key details:
- Clear Ownership: Assign the action to a specific person or team. "The infrastructure team will..." is just too vague. "John Smith, Lead Systems Engineer, will..." creates real accountability.
- Firm Deadlines: Every action needs a realistic but firm completion date. This demonstrates to auditors that you're managing the remediation with genuine urgency and a structured plan.
- Verifiable Outcomes: How will you prove the action was completed and actually worked? This could be a screenshot of a new firewall rule, a follow-up vulnerability scan report, or an updated and signed-off policy document.
Think about a phishing incident. The immediate technical fix is to block the malicious domain. But the corresponding CAPA would formalize this into a much broader, more strategic improvement.
An auditor's primary goal is to verify that your ISMS functions as a cycle of continuous improvement. A well-documented CAPA, born from a real-world incident, is the strongest possible evidence you can provide. It proves your system isn't just theory; it works in practice.
Explicitly Connecting Incidents to ISO 27001 Controls
The next step is to draw a direct line from the incident and its CAPAs back to specific controls within the ISO 27001 framework. This isn't just good practice; it's a non-negotiable requirement for demonstrating the effectiveness of your controls. You’re essentially telling the auditor, "We understand precisely how this specific failure relates to our overall security framework, and here's how we strengthened that link."
Let's walk through a common scenario: a successful phishing attack that led to a credential compromise.
Incident Scenario: A Phishing Attack
A sophisticated phishing email snuck past your spam filter. An employee, unfortunately, entered their credentials into a convincing fake login portal. Your team spotted the anomalous login activity, contained the breach, and immediately forced a password reset.
Here’s how you would map the lessons learned back to ISO 27001 controls right in your incident report:
| Incident Finding | Relevant ISO 27001 Control (Annex A) | Documented CAPA |
|---|---|---|
| The phishing email was not blocked by existing filters. | A.8.23 Web filtering | CAPA-1: Review and enhance email gateway rules to better detect spoofed domains. Owner: Security Team. Due: 14 days. |
| The employee did not recognize the signs of a phishing attempt. | A.5.10 Acceptable use of information and other associated assets | CAPA-2: Update the annual security awareness training to include new modules on identifying sophisticated phishing tactics. Owner: GRC Manager. Due: 30 days. |
| The compromised credentials could have been used for lateral movement. | A.8.5 Secure authentication | CAPA-3: Accelerate the rollout of multi-factor authentication (MFA) to all remaining user accounts. Owner: IT Director. Due: 90 days. |
A table like this does so much more than just list fixes. It builds a compelling narrative for the auditor, showing exactly how a real-world failure led directly to specific, measurable improvements in your control environment. This methodical approach transforms a negative event into powerful proof of a healthy, responsive ISMS.
Streamlining Evidence Collection for Faster Reporting
The moment an incident is declared, the frantic scavenger hunt begins. I've seen it a hundred times: security teams are thrown into a sea of disparate data, digging through endless Slack threads, forwarding emails, and trying to make sense of server logs. This manual scramble is the single biggest bottleneck in creating solid security incident reports. It’s slow, it’s messy, and you’re almost guaranteed to miss something important.
Trying to piece together a coherent timeline from all those fragments is a massive headache. A critical decision made in a direct message gets overlooked. A key log file isn't pulled until hours after the fact. This chaos doesn't just delay the report; it creates gaps that auditors will find and pick apart.
A Modern Workflow for Evidence Management
Now, imagine a different way. Instead of chasing down artifacts one by one, you centralize everything—emails, chat exports, log files, screenshots, user reports—into a single, secure place. This is where modern tooling, especially AI-powered analysis, can completely change the game.
By uploading all relevant documents, you create a unified "evidence locker" for that specific incident. From there, an intelligent agent can do the heavy lifting that would normally take a team days to get through.
The diagram below shows how this centralized workflow takes all that chaotic input and turns it into organized, useful output.
This really highlights the shift away from a scattered, manual process to a structured flow. Technology isn't replacing the analyst; it's giving them superpowers to find the truth faster.
The whole point is to let technology handle the tedious work of finding needles in the haystack. That frees up your team to focus on the strategic analysis and response. With the right tools, you can get from initial evidence collection to a drafted report in hours, not days.
Using AI to Extract and Cite Evidence
Once your evidence is all in one place, an AI agent can step in to do a few things that radically speed up the reporting process. This kind of tech is built to read and understand unstructured content, spotting connections that a person under pressure might easily miss.
Here’s what it can actually do for you:
- Timeline Extraction: The AI scans everything and automatically pulls out key events with timestamps. For example, it can grab "User A reported suspicious activity at 14:05 UTC" from an email and put it right next to a server log entry from 14:10 UTC in a clean timeline.
- Evidence Surfacing: You can ask it plain-English questions like, "Show me all communications about isolating the affected server." The AI will pull the exact snippets from Slack, emails, or team reports that answer the question, complete with direct citations to the source.
- Gap Identification: The system can also point out where your story is weak. If the timeline jumps from initial detection straight to remediation with no documented investigation, the AI can flag that as a potential gap, telling you exactly what you still need to find.
The real game-changer here is the citations. Every piece of information the AI pulls is directly linked back to the source document, page, and line. This creates a rock-solid, evidence-backed report that makes an auditor's job—and your life—much easier.
Building a Cleaner Package for Auditors
The result of all this isn't just a faster report. It's a cleaner, more organized, and far more defensible evidence package. When an auditor asks for proof of a specific action, you’re no longer digging through your inbox or a dozen different shared folders.
Instead, you can point to the exact citation in the report, which links directly to the source artifact. This level of organization and transparency proves you have a mature, methodical incident response process. It shows your actions are not just documented but are backed by verifiable proof. This automated approach is a core principle behind effective compliance assessment software, which is designed to make evidence gathering as painless as possible.
By adopting this kind of workflow, you move from a reactive scramble to a proactive, structured investigation. The final report becomes a clear narrative of your organization's diligence, supported by a clean, easy-to-follow trail of evidence that will stand up to even the toughest scrutiny.
Got Questions About Incident Reporting? We've Got Answers.
Even with the best playbook, you're going to run into questions when you're in the middle of writing up an incident. Let's walk through some of the most common things that trip up GRC pros and security analysts, with some straight-up advice from the trenches.
How Much Detail Is Too Much?
You're aiming for clarity, not a novel. The golden rule is to include just enough detail for another technical person to read your report, reconstruct the event, understand what you did, and nod in agreement with your conclusions. It's all about relevance.
Cut out the speculation and the overly deep technical jargon that doesn't actually move the story forward. For instance, logging every single failed login attempt is probably just noise. But documenting the one successful unauthorized login? That's the whole point. If a detail doesn't help explain how you detected, responded to, or fixed the problem, it's likely just clutter.
When Does an "Event" Become an "Incident"?
This is a critical distinction that absolutely must be spelled out in your incident response plan. Without a clear definition, you get inconsistency and hesitation when it matters most. Generally, an event gets promoted to an incident the moment it poses a real threat to the confidentiality, integrity, or availability (the classic CIA triad) of your company's data or systems.
Look for triggers like these:
- Confirmed unauthorized access to sensitive systems or PII.
- Malware successfully detonates and you have to actively clean it up.
- A major system outage is actively hurting the business.
- A company laptop with sensitive info goes missing.
When you have these criteria defined ahead of time, there’s no guesswork. You can kick off the formal response process without wasting precious minutes.
What's the Single Biggest Mistake to Avoid?
I see it all the time: a weak or lazy root cause analysis (RCA). Just writing "a user clicked a phishing link" is a description of a symptom, not a root cause. An auditor sees that and immediately thinks you aren't serious about continuous improvement.
A proper RCA goes deeper. It asks why. Why didn't our email security block the phishing attempt? Why wasn't the user trained well enough to spot it? Why did our endpoint protection fail to stop the payload from running? Ignoring these systemic failures is a huge red flag that you're just waiting for the next incident to happen.
Can an Incident Report Template Be Too Rigid?
Oh, absolutely. A standardized template is fantastic for making sure you don't miss the critical stuff. But it has to have some give. The information you need to document for a widespread malware infection is completely different from what's required for a lost company laptop.
The threat landscape moves way too fast for a one-size-fits-all approach. Just look at the chaos from June 2025. We saw 33 publicly disclosed security incidents that month, capped off by a mind-boggling compilation of 16 billion user credentials from older data thefts. Even setting that massive number aside, over 23 million new records were freshly compromised. This stuff is constant and comes in all shapes and sizes, as you can see in the full rundown of global data breaches on GRCSolutions.io.
The best bet is a hybrid approach. Start with a core template that has your non-negotiables—timeline, business impact, root cause—but build in flexible sections you can tailor to the specific type of incident. That way, you get the best of both worlds: consistency and relevance.
Tired of the manual scavenger hunt for audit evidence? AI Gap Analysis uses an intelligent agent that reads your documents, pulls out the key findings, and gives you instant citations. It can turn a stack of PDFs into an evidence-ready report in a fraction of the time. See how to get to compliance faster at https://ai-gap-analysis.com.